

「セイテク・シス管道場(Web)」では、Windows Serverの要素技術やシステム管理の基本的な部分に焦点を当てたいと思います。前回は「パフォーマンスモニター」(perfmon)を取り上げましたが、今回はパフォーマンスモニターやその他のWindowsのツール、外部監視ツールが扱うパフォーマンスカウンターの方に注目します。
一般的なパフォーマンスカウンターとその意味するところ
パフォーマンスカウンターは、システム全体のリソース使用量から、実行中のプロセスやそのプロセスのスレッド単位でのCPU、メモリ、ディスクI/Oの挙動に至るまでを可視化し、ボトルネックの特定やパフォーマンス評価を行うための基盤となる指標(メトリック)を提供します。Windowsは膨大なパフォーマンスカウンターを提供しますが、各カウンターの示す値については、パフォーマンスモニターの「カウンターの追加」で「説明を表示する」をチェックすることで確認できます(画面1)。
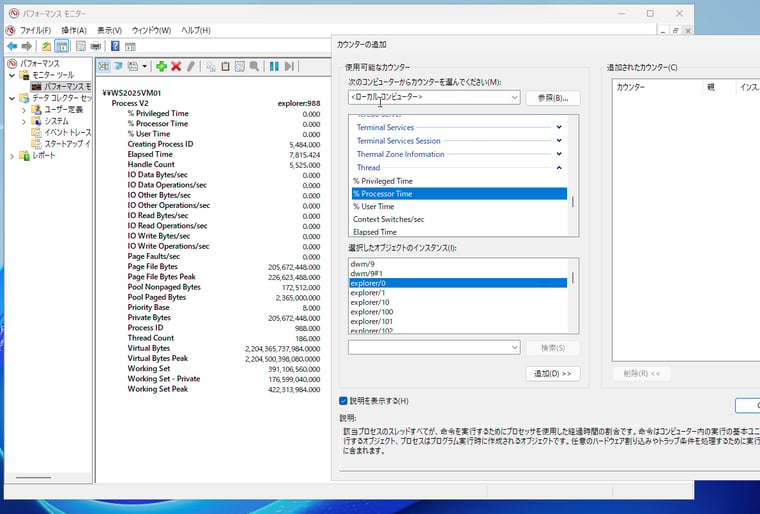
画面1 パフォーマンスカウンターを使用すると、実行中のプロセス*1 やスレッドの単位まで細かくリソース使用量を観察できる
*1 Process V2カウンターオブジェクトは、インスタンス名が重複して識別できない(例、explorer)という従来のProcessカウンターオブジェクトの問題を解消するために、インスタンスにプロセスIDを付加(例: explorer:988)した新しいオブジェクトで、Windows 11およびWindows Server 2022以降で利用可能です。
→ 重複するインスタンス名の処理|Windowsアプリ開発(Microsoft Learn)
実際のところ、スレッドの単位まで細かくリソース使用を追跡する目的でパフォーマンスカウンターを使用することはないでしょう。システムのパフォーマンスを評価するには、まず、一般的なカウンターに着目して、プロセッサ(CPU)、メモリ、システム、物理ディスク、ネットワークインターフェイスのパフォーマンスを調査します。
ここでは、Microsoft公式のトレーニングからラーニングパス「Windows サーバー環境の監視とトラブルシューティングを行う」のユニット2「パフォーマンス モニターを使用してパフォーマンスの問題を特定する」(Microsoft Learn)で紹介されているパフォーマンスカウンターをベースに、いくつか付け加えて説明します。先に言っておきますが、公式のラーニング素材だからといって、現在のシステムにそのまま適用できるとは限りません。
プロセッサ(CPU)
\Processor(_Total)\% Processor Time
\Processor Information(_Total)\% Processor Time
Processorカウンターオブジェクトの% Processor Timeカウンターは、アイドルでないスレッドの実行にCPUが費やした時間の割合を測定します。この値が継続して85%を超えている場合は、CPUがボトルネックになっている可能性があると(ラーニングパスでは)説明されています。CPUがボトルネックになっている場合は、高速なCPUへの入れ替え、CPUの追加、あるいは現在担っているサーバーの役割の一部を別のサーバーに分散するなど検討したほうがよいということになります。
現在、Processorカウンターオブジェクトのカウンターは、Windowsにプロセッサグループという概念が登場する以前(最大64論理プロセッサに対応したWindows Server 2008以前) から存在するレガシなカウンターの1つです。以下の記事で説明したように、現在はメニーコア(64を超えるコア)、クロック周波数の変動、NUMAシステムに対応したProcessor Informationカウンターオブジェクトの使用が推奨されています。以下の記事では、タスクマネージャーとのからみで、100%を超えることがある% Processor Utilityカウンターの値をタスクマネージャー用に0~100%に換算する方法を紹介しましたが、これにこだわる必要はありません。しきい値監視には上限が100%の% Processor Timeのほうが扱いやすいでしょう。もちろん、新しいProcessor Informationカウンターオブジェクトのほうの% Processor Time です。
vol.199 タスクマネージャーが示すCPU情報と使用率の秘密||セイテク・シス管道場(Web)
\System\Processor Queue Length
CPUのキューにあるスレッド数を示します。このカウンターが論理プロセッサの数の2倍を長時間にわたって超えている場合は、サーバーのCPU能力が不足していると言われてきました。シングルコアや少数のコアの時代なら、おそらくそのとおりでした。しかし、論理プロセッサ数が増え、スケジューリングが高度化し、CPUを待機する種類(ロック待ち、I/O待ち、同期処理など)が増えた現在、キュー長の多少の増加は珍しくありません。ただし、同時に全体のプロセッサー使用率が非常に高い状態を示しているなら、論路プロセッサ数の2倍という従来の目安は参考にできるでしょう。
メモリ
\Memory\Available Bytes、Available KBytes、Available MBytes
このカウンターはすぐに利用可能な物理メモリのサイズをバイトまたはMBで示します。この値は、完全に未使用なメモリ(Free & Zero Page List Bytes)とスタンバイメモリ(Standby Cache Core Bytes、Standby Cache Normal Priority Bytes、Standby Cache Reserved Bytes)の合計と一致します。
PowerShellでやってみよう!システムに搭載されている物理メモリの容量は、WMIのWin32_OperatingSystemクラスのTotalVisibleMemorySizeプロパティから取得できます。また、Available Bytesカウンターと同じ値を、同じWMIクラスのFreePhysicalMemoryプロパティから取得することもできます。メモリ使用率を算出する次の2つのPowerShellのコードは、同じ値を示すはずです。 $w32os = Get-CimInstance Win32_OperatingSystem
$ramtotal = $w32os.TotalVisibleMemorySize $ramfree = (Get-Counter "\Memory\Available Bytes").CounterSamples.CookedValue "RAM {0:N2} %" -f (($totalmem - $avairablemem) / $totalmem * 100) $w32os = Get-CimInstance Win32_OperatingSystem
$ramtotal = $w32os.TotalVisibleMemorySize $ramfree = $w32os.FreePhysicalMemory "RAM {0:N2} %" -f (($totalmem - $avairablemem) / $totalmem * 100) 
(メモリ使用率の算出) |
\Memory\Pages/sec
このカウンターは、ハードページフォールトを解決するためにディスクから読み取れられた、またはディスクに書き込まれた秒あたりのページ数です。過剰なページングによりこのカウンターが1,000を超えている場合は、メモリリークの疑いがあります。メモリリークの疑いは、MemoryカウンターオブジェクトのPool Nonpaged Bytesカウンターの増加傾向からも判断できます。
ディスク
\PhysicakDisk(インスタンス)¥% Disk Time
\PhysicakDiskまたはLogicalDisk(インスタンス)¥% Idle Time
※ユーザーやアプリケーションの視点での監視、およびRAID構成や記憶域スペースを監視する場合はLogicalDiskが適切です。ハードウェア視点の監視、例えばハードウェア異常を見るにはPhysicalDiskが適しています。(以下、同じ)
% Disk Timeカウンターは、選択したディスク(インスタンス)がサンプリング間隔中にビジー状態になった時間の割合をパーセント(%)で示します。一方、% Idle Timeカウンターはディスクがアイドルだった時間を示します。これまで% Disk Timeカウンターはタスクマネージャーの「パフォーマンス|ディスク」の「アクティブ時間(%)」に相当するもので、値が85%を超える場合は、ディスクシステムが飽和状態の可能性があるとされてきました。しかし、実はこの値は次に説明するAvg. Disk Queue Lengthに100をかけた値を単に示しており(Avg. Disk Queue Lengthが1なら100%)、現在のシステムでは100%をはるかに超える値を示すことがあります(画面2)。
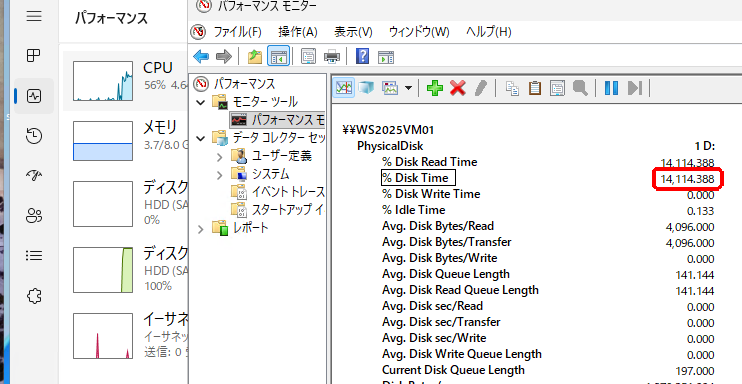
画面2 % Disk Timeは指標としては使いものにならない。ディスクのアクティブ時間を知りたければ100%-% Idle Time(この例では100-0.133=99.867%)
現在では、ディスクスピンドルを持たないSSDやNVMeが一般化し、HDD以外ではAvg. Disk Queue Lengthの値はほとんど意味をなくしました。SSDは並列にI/Oを処理できるため、数百以上のキュー長でも問題なく処理できます。そのディスクキュー長に100をかけるため、% Disk Timeは100%をはるかに超える値を示すことになります。そのため、現在は、% Disk Timeを使用するべきでありません。% Disk Timeの代わりに、ディスクがアイドルだった時間の割合を示す% Idle Timeカウンターを使用できます。100ー% Idle Timeが求めるディスクのアクティブ時間(%)を取得できます。また、ディスクのアクティブ時間が85%を超えたとしても、それだけでディスクシステムの飽和状態と判断するべきではありません。ディスクのアクティブ時間よりも、レイテンシ(応答時間)が悪化していないかどうかのほうがが重要です。
参考:
Windows Performance Monitor Disk Counters Explained|Ask the Core Team(Microsoft Learn)
\PhysicalDiskまたはLogicalDisk(インスタンス)\Avg. Disk Queue Length
このカウンターはディスクが使用可能になるのを待機しているI/O操作の数を示します。正常値は0であり、値がスピンドルの2倍を超えている場合は、ディスクがボトルネックになる可能性があると言われています。しかし、それはHDD(ハードディスクドライブ) の話です。先ほど説明したように、ディスクスピンドルがないSSDやNVMeではこの値が高くてもまったく問題ありません。
\PhysicalDiskまたはLogicalDisk(インスタンス)\Avg. Disk sec/Read
\PhysicalDiskまたはLogicalDisk(インスタンス)\Avg. Disk sec/Write
これらのカウンターは、このディスクからのデータ読み取り時間、ディスクへの書き込みの時間の平均秒数を、つまりディスクのレイテンシ(シーク時間や回転待ち時間などの遅延)を示します。一般的にHDDは5~15ms、SSDは1~5ms、NVMeは0.1~1ms、ネットワークストレージは1~20msが標準的です。20msを超えるとボトルネックの可能性があります。
\PhysicalDiskまたはLogicalDisk(インスタンス)\Disk Read Bytes/sec
\PhysicalDiskまたはLogicalDisk(インスタンス)\Disk Write Bytes/sec
このカウンターは、読み取り、書き込み操作中のディスクのバイト転送速度を示します。これらの値からディスクのスループット(MiB/sやMB/s)がわかります。
|
ディスクのスループット(MiB/s) = (Disk Read Bytes/sec + Disk Write Bytes/sec) / 1024 / 1024 または |
※MiBはメビバイト、MBはメガバイト
\PhysicalDiskまたはLogicalDisk(インスタンス)\Disk Reads/sec
\PhysicalDiskまたはLogicalDisk(インスタンス)\Disk Writes/sec
これらのカウンターは、読み取り操作中、書き込み操作中のディスクの転送速度を示します。これらの値からIOPSを算出できます。
| ディスクの IOPS = Disk Reads/sec + Disk Writes/sec |
PowerShellでやってみよう!次のPowerShellのコードは、PhysicalDisk/LogicalDiskカウンターオブジェクトのカウンターを取得して、D:ドライブ(インスタンス名 1 d:)のディスクパフォーマンスを出力するサンプルです。出力結果は、1行目のコマンドラインを実行した時点の瞬間値(直近の1秒間のサンプル間隔の値)です。 $csamples = get-counter "\PhysicalDisk(インスタンス名)\*" |Select-Object -Expand CounterSamples
#インスタンス名は (Get-Counter -ListSet PhysicalDisk).PathsWithInstances を実行して確認してください。例、 0 c: foreach ($c in $csamples) { switch ($c.Path) { {$_ -match "% Idle Time"} {$diskidle = $c.CookedValue} {$_ -match "Avg. Disk Queue Length"} {$adiskq = $c.CookedValue} {$_ -match "Avg. Disk sec/Read"} {$adiskspr = $c.CookedValue} {$_ -match "Avg. Disk sec/Write"} {$adiskspw = $c.CookedValue} {$_ -match "Read Bytes/sec"} {$rbps = $c.CookedValue} {$_ -match "Write Bytes/sec"} {$wbps = $c.CookedValue} {$_ -match "Disk Reads/sec"} {$drps = $c.CookedValue} {$_ -match "Disk Writes/sec"} {$dwps = $c.CookedValue} } } $outstr = "% Disk Time : {0:N2} %" -f (100 - $diskidle) $outstr += "`nAvg. Disk Queue Length : {0:N2}" -f $adiskq $outstr += "`nAvg. Disk sec/Read : {0:N2} ms" -f ($adiskspr * 1000) $outstr += "`nAvg. Disk sec/Write : {0:N2} ms" -f ($adiskspw * 1000) $outstr += "`nThroughput : {0:N2} MiB/s" -f $(($rbps + $wbps) / 1024 / 1024) $outstr += "`nIOPS : {0:N2}" -f ($drps + $dwps) $outstr 次の画面は、SSDディスク上に配置されているHyper-V VMで、意図的に高いディスクI/O負荷を与えた状態で実行した結果です。Avg. Disk Queue Lengthが高い値を示していますが、ディスク時間は100%ではありません。このことから、Avg. Disk Queue Lengthが論理プロセッサ数×2というしきい値は何の目安にもならないことがわかるでしょう。
(ディスクI/Oの負荷テスト中に実行) |
ネットワーク
\Network Interfacek(インスタンスまたは*)\Bytes Total/sec
Network InterfaceカウンターオブジェクトのBytes Total/secカウンターは、ネットワークインターフェイスが1秒あたりに送受信したバイト数を示します。このカウンターがネットワークインターフェイスの帯域(Current Bandwidthカウンター)の70%以上使用されている場合は、ネットワークが飽和状態の可能性があります。ただし、仮に帯域の100%であったとしても、性能を最大限に使い切っているのかもしれません。後で出てくるキューの詰まりやエラー数と合わせて見る必要があります。なお、VM環境の場合、ネットワークインターフェイスが示すCurrent Bandwidthは物理ホストのネットワークインターフェイスの帯域を反映しており、実際の帯域を示しているわけではないことに注意してください。例えば、同一の物理ホスト上の2台のVMの場合、VM間の通信は物理的なネットワークに出ていくことはなく、ホストのメモリ間コピーで完結するため、帯域をはるかに超える性能が出ます。
|
スループット(Mbps) = Bytes Total/sec × 8 / 1000000 または Bytes Sent/sec + Bytes Received/sec × 8 / 1000000 帯域使用率(%) = (Bytes Sent/sec とBytes Received/sec の大きいほう)×8 / Current Bandwidth * 100 |
\Network Interface(ネットワークインターフェイス)\Output Queue Length
Network InterfaceカウンターオブジェクトのOutput Queue Lengthカウンターは、出力パケットキューの長さをパケット単位で示します。このカウンターが2を超えている場合は、ネットワークが飽和状態の可能性があります。
\Network Interfacek(インスタンスまたは*)¥Packets Outbound Errors
\Network Interfacek(インスタンスまたは*)¥Packets Received Errors
送信/受信エラーパケット数を示します。0が正常です。
パフォーマンスカウンターとの付き合い方、その1
パフォーマンスカウンターは、従来からシステムの状態把握やボトルネック特定に有効な手段ですが、近年では新しいハードウェア(SSDやNVMe、10GbE)や環境の多様化(VMやクラウド環境)の変化により、その解釈や活用方法も変わってきています。Windowsにも新しい世代のカウンターオブジェクトが追加されています(Processor InformationやProcess V2など)。これまで常識と思っていた経験則では、単純にしきい値で監視することはできないこともあります。使用率100%を即問題と判断するのは間違いであり、複数のカウンター値を適切に評価して判断する必要があります。
CPU、ディスク、ネットワークのパフォーマンスついては、ハードウェアの性能や仕様上の上限以外に、QoS制限(OSのQoS制限、Hyper-VやSMBのQoS制限、Azure VMのサイズによるCPUクレジットやIOPSやスループットの上限など)の有無についても考慮する必要があります。例えば、QoS制限があると、ディスクのIOPSやスループット、ネットワークのスループットが100%より下で頭打ちになります。同じ100%でも本当に飽和状態で性能の限界なのか、低い負荷に見えても実はQoS制限で頭打ちになっているのではないかなど、実行環境を含めて総合的に判断する必要があります。
以下の製品コラムでは、パフォーマンスカウンターを単純に監視するのではなく、BOM for Windowsのカスタム監視の機能を利用して、メモリ、ディスク、ネットワークのパフォーマンスを効果的に監視する方法を紹介しています。
メモリ/ハンドルリークを監視したい-BOM for Windows活用例|製品コラム
ディスクとネットワークのパフォーマンス監視がしたい-BOM for Windows活用例|製品コラム
カスタム監視のベストプラクティス-BOM for Windows FAQ(仮)|製品コラム
セイテク・シス管道場(Web) (1) |(2)|(3)|(4) |(5)|(6) |(7)|(8)|(9)|(10)|(11)




