


「セイテク・シス管道場(Web)」では、Windows Serverの要素技術やシステム管理の基本的な部分に焦点を当てたいと思います。このシリーズの後半はパフォーマンスカウンターについて掘り下げてきましたが、今回は仮想環境におけるパフォーマンスについて取り上げます。
仮想環境特有のパフォーマンスの考慮事項
オンプレミスやクラウドの仮想環境におけるパフォーマンス監視は、仮想化プラットフォーム(オンプレミスの仮想化ホスト、クラウドのプラットフォーム)と仮想マシン(VM)の安定稼働と効率的なリソース活用のために重要です。物理環境とは異なり、仮想環境では複数のVMが同じホストのリソースを共有することになり、CPU、メモリ、ストレージ、ネットワークの各リソースは相互に影響を受けるため、単一の指標(メトリック)だけではボトルネックの特定が困難な場合があります。そのため、仮想化ホストのOSとVMのゲストOSの両方の視点から、パフォーマンスを継続的に監視し、総合的に評価することが重要です。その結果、ボトルネックが判明したら、オンプレミスであれば、仮想化ホストのハードウェアの増強、VMのリソース割り当て変更、他のホストへのVMの移動、過剰なリソース使用に対するQoS(サービス品質)制限などで対処します。クラウドであれば、VMのサイズの見直しや、ディスクの種類の変更、ディスク数やネットワーク数の追加を検討します。
Hyper-Vホストのボトルネックの検出
オンプレミスの仮想化プラットフォームがHyper-Vである場合は、Hyper-Vホストで以下のパフォーマンスカウンターに注目します。
プロセッサ
| \Hyper-V Hypervisor Logical Processor(_Total)\% Total Run Time | すべての論理プロセッサ合計で90%を超える場合、ホストがオーバーロードの状態。CPUの処理能力を増強するか、一部のVMを別のホストに移動するべき。 |
| \Hyper-V Hypervisor Virtual Processor(*)\% Total Run Time | VMのすべての仮想プロセッサ(VM名: Hv VP *)で90%を超える場合、VMに仮想CPUを追加する。VMの一部のVPで90%を超える場合、ネットワーク負荷の高いVMではvRSSの使用やNICの追加を、ストレージ負荷の高いVMではネットワークで仮想NUMAやディスクを追加。 |
| \Hyper-V Hypervisor Root Virtual Processor(*)\% Total Run Time \Processor(*)\% DPC Time \Processor(*)\% Interrupt Time |
すべてではなく、一部のルート仮想プロセッサ(Root VP x)が90%を超える場合で、その値が¥Processor(x)¥ % DPC Timeと¥ Processor(x)¥ % Interrupt Timeの合計を超える場合、その仮想プロセッサを使用するVMのネットワークアダプターでVMQを有効化するべき。 |
メモリ
| \Memory\Available MBytes \Hyper-V Dynamic Memory Balancer(*)\Available Memory |
両方のカウンター(単位はMB)が低い場合、ホストで不要なサービスを停止するか、VMを別のホストに移動するべき。VMのゲストでAvailable Mbytesが低い場合は、追加の固定メモリを割り当てるか、動的メモリの最大RAMを増やせばよい。 |
Hyper-VホストからVMの(疑似)メモリ使用率を取得する方法Hyper-VホストからVMのパフォーマンスカウンターを取得する方法としては、Hyper-VのPowerShell Directを利用する方法があります(Invoke-Command -VMName "VMNAME" {スクリプトブロック})が 、認証情報(-Credential)が要求されることがありますし、そもそもLinux VMにはWindowsのパフォーマンスカウンターはありませんし、PowerShell Directも使用できません。 代替方法として、Get-VMのMemoryAssigned(割り当てメモリ《バイト》)とMemoryDemand(要求メモリ《バイト》)プロパティから疑似的なメモリ使用率を算出することができます。
(Get-VMのプロパティから疑似的なメモリ使用率を算出する) Get-VMにはCPUCount(仮想CPU数)プロパティもあります。次のコードを実行すれば、実行中のすべてのVMのCPU数、CPU使用率、メモリ割り当て(MB)、および疑似メモリ使用率を一覧で取得することができます。“疑似的”と断ったのは、MemoryDemandプロパティが動的メモリ制御用の指標であり、実際の使用中メモリではないからです。この疑似的なメモリ使用率は100%を超えることがあり、動的メモリが有効ならメモリバッファー(既定、20%)を加味してメモリが追加され、すぐに100%未満(100ーメモリバッファー%)に最適化されるでしょう。動的メモリがオフの場合、100%以上の値が続くため、メモリ不足の状況を判断でき、メモリ割り当てのサイズの目安にできます。 $result = Get-VM | ForEach-Object {
if ($_.State -eq 'Running') { $cpu = $_.CpuUsage if ($_.MemoryAssigned -gt 0) { $mem = [math]::Round(($_.MemoryDemand / $_.MemoryAssigned) * 100, 2) } else { $mem = 0 } [PSCustomObject]@{ VMName = $_.Name CPUCount = $_.ProcessorCount CPUUsage = $cpu RAMMb = [math]::Round($_.MemoryAssigned / 1024 / 1024,0) RAMUsage = $mem } } } $result | Format-Table (CPUとメモリの割り当て、および使用率を一覧表示) |
ディスク
| \PhysicalDiskまたはLogicalDisk(インスタンス)\Avg. Disk sec/Read \PhysicalDiskまたはLogicalDisk(インスタンス)\Avg. Disk sec/Write \PhysicalDiskまたはLogicalDisk(インスタンス)\Avg. Disk Read Queue Length \PhysicalDiskまたはLogicalDisk(インスタンス)\Avg. Disk Write Queue Length |
Avg. Disk sec/ReadまたはAvg. Disk sec/Write(ディスクのレイテンシ)が50msより大きい場合、物理ディスクを追加してVMの配置を分散する、より高速な記憶域を導入する、階層化記憶域スペース(SSD+HDDなど)の使用を検討する、過剰にディスクI/Oを行っているVMを特定し、ストレージQoS(サービスの品質の管理)で最大IOPSを設定して制御する(画面1)などを検討するべき。 |
※ユーザーやアプリケーションへの影響を見る場合、複数のディスクで構成されるソフトウェアRAIDや記憶スペースの場合は、PhysicalDiskではなく、LogicalDiskで監視することをお勧めします。
ネットワーク
| \Network Interface(インスタンス)\Bytes Total/sec | ネットワークアダプターの帯域の90%を超える場合、ホストに物理ネットワークアダプターを追加するか、VMを別のホストに移動するべき。過剰にネットワークを使用するVMがある場合は、ネットワークのQoS(帯域幅管理)で最大帯域幅(例、10000.0Mbps《10Gbps》)を設定して制御することもできる(画面2)。 |
| \Hyper-V Virtual Network Adapter(インスタンス)\Bytes/sec | インスタンスが(Hyper-V仮想スイッチではなく)VMのネットワークアダプターの場合、VMにNICを追加するか、vRSSとSR-IOVを有効化するべき。 |
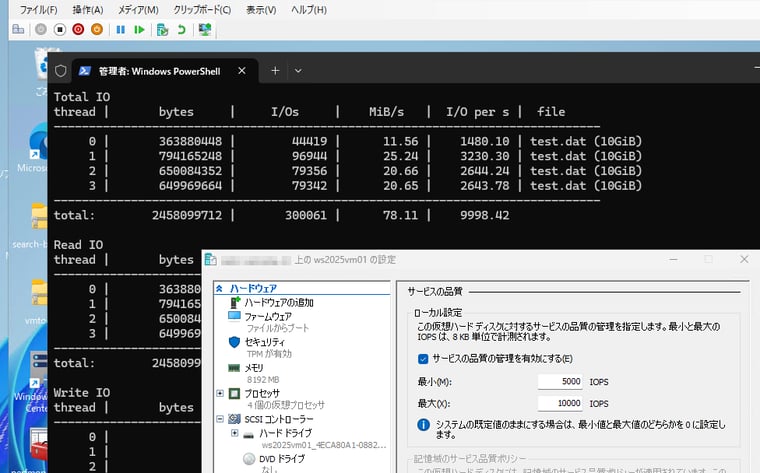
画面1 Hyper-VのストレージQoS(サービスの品質)機能を使用して、IOPSに上限を設定する。VM側のIOPS値は、前回紹介したDiskspdで測定
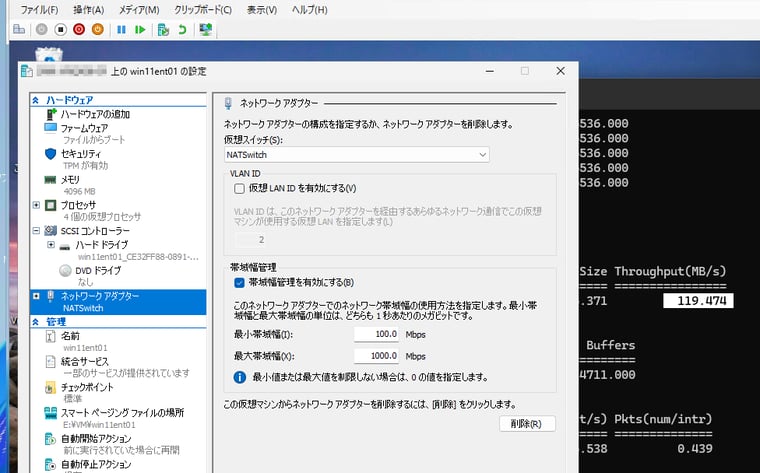
画面2 Hyper-VのネットワークQoS(帯域幅管理)機能を使用して、VMのネットワーク使用に上限を制限する。VM側のスループット値は、前回紹介したNTTTCPで測定
ここで示したパフォーマンスカウンターは、パフォーマンスモニターのユーザー定義データコレクターセットを使用して一定期間(数日、数週間など)ログに記録し、その後、パフォーマンスを分析するとよいでしょう(画面3)。ログの分析は、前々回(vol.204)で紹介したImport-Counterコマンドレットによる集計が便利です。詳しくは、おまけに掲載しておきます。
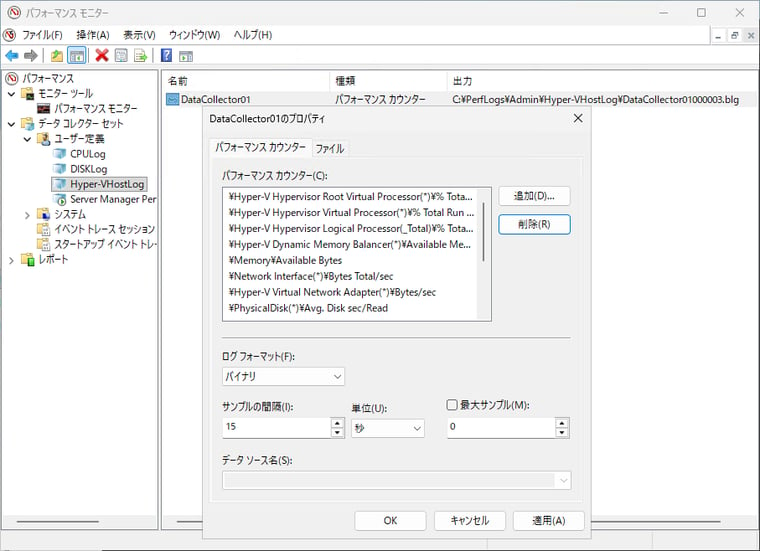
画面3 仮想環境の監視で注目したいパフォーマンスカウンターをデータコレクターセットを用いてログに記録する
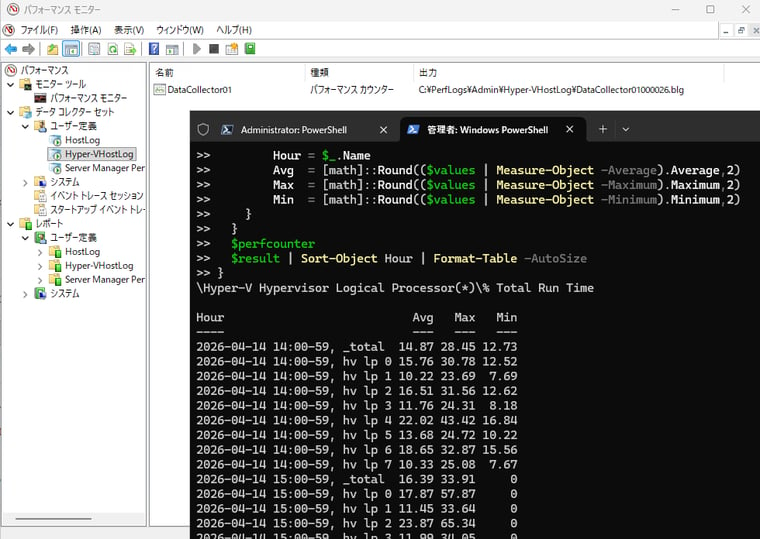
画面4 データコレクターセットのログをPowerShellで集計
参考:
仮想化された環境でのボトルネックの検出|Windows Server(Microsoft Learn)
おまけvol.205と同じように、今回紹介したHyper-Vホスト向けパフォーマンスカウンターを取得する画面3のデータコレクターセット「Hyper-VHostLog」のテンプレートファイル(dcs_Hyper-VHostLog.xml)と画面4で使用した集計用PowerShellスクリプト(sample04.ps1)を用意しました。次のように、Logmanコマンドを使用してインポートし、ログの記録を開始できます。 ログの記録は直ちに始まりますが、バッファーがディスクに書き込まれるまでしばらく時間がかかります。 最後のスケジュール設定は、システム起動時に自動開始させるためのものです。
このデータコレクターセット「Hyper-VHostLog」は、各パフォーマンスカウンターを15秒間隔でログファイル「C:¥perflogs¥Admin¥Hyper-VHostLog¥DataCollector01NNNNNN.blg」(NNNNNNは連番)に記録し、24時間(86395秒)ごとに停止して新しいログで再開し、各ログは30日後に削除するように、データマネージャーで設定してあります。 集計用PowerShellスクリプト(sample04.ps1)は、最大過去24時間(ログがある場合)、1時間ごとの各パフォーマンスカウンターの平均、最大、最小値を一覧表示します。 |
Hyper-Vのリソースメータリング機能
Windows Server 2012以降のHyper-Vでは、リソースメータリング機能を使用して、VMごとのCPU時間(Mhz、CPU使用率×クロック周波数)、メモリ使用量(平均、最大、最小MB)、ディスク(合計MB)、ネットワーク(受信/送信MB)をホスト側から計測できます。特定のVMでリソースメータリングの計測を開始するには、次のコマンドラインを実行します。
| Enable-VMResourceMetering -VMName "VM名" (コマンド終了後、Disable-VMResourceMeteringで無効化するまで計測) |
計測データを参照、リセット、計測の終了には、以下のコマンドラインを実行します。
|
Get-VM -Name "VM名" | Measure-VM Get-VM -Name "VM名" | Reset-VMResourceMetering |
リソースメータリングで計測できるネットワーク使用量は、VMのすべてのネットワークアダプターの合計です。VMのポートACL機能を利用すると、特定の宛先は送信元のIPアドレス、IPアドレス範囲ごと、ネットワークアダプターごとのネットワーク使用量を計測できます。それには、次のコマンドラインを順番に実行します。
|
Add-VMNetworkAdapterAcl -Action Meter -Direction Both -VMName "VM名" -RemoteIPAddress "ANYまたはIPv4/v6アドレスまたはサブネット"" [-VMNetworkAdapterName "ネットワークアダプター名"] Get-VMNetworkAdapterAcl -VMName "VM名" | Remove-VMNetworkAdapterAcl |
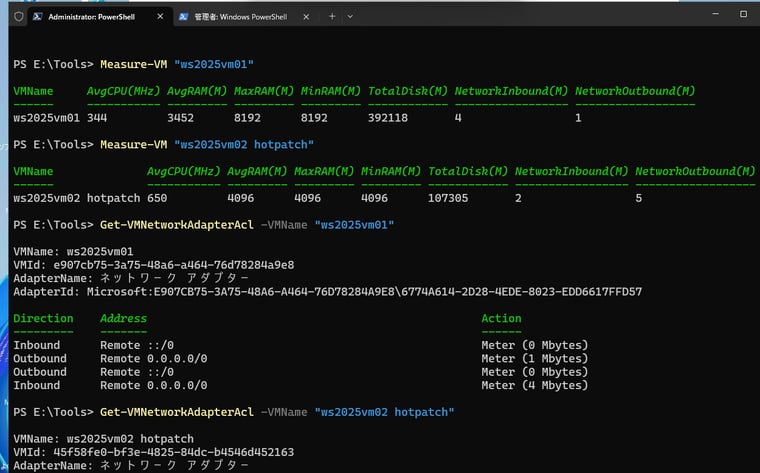
画面5 Hyper-VのリソースメータリングおよびポートACLを利用した、VMのリソース使用量の計測
Azure VMのホストメトリック
クラウド環境の例としてAzureで説明します。Azure VMのCPUのモデル、コア数、メモリはVMのサイズによって固定されています。VMのサイズは変更可能なので、これらのリソース不足にはサイズの変更で対応できます。Bシリーズはクレジット制であり、クレジットの蓄積や消費により、CPUの使用が制限されます。
ディスクとネットワークについては、VMのサイズによって最大IOPSや最大スループット(Mbps)、データディスク数やネットワーク数が制限されます(画面6)。ディスクについては、マネージドディスクの種類(Premium SSDやStandard SSD)とサイズでも最大IOPSと最大スループットが制限されます(画面7)。Premiumディスクでは、プロビジョニングされた最大IOPSや最大スループットを超えたバーストに対応しています。IOPSが低い場合、クレジットが蓄積され、IOPSを超えたとき、最大バーストIOPSや最大バーストスループットの範囲でクレジットが使用されます。
例えば、VMのサイズでディスクの最大IOPSが6400まで提供されるとしても、Premium SSDの512GiBディスク(S20)のIOPSは500なので、1つのディスクでは500 IOPSまでしか出ません。VMのサイズの最大IOPSを得るには複数のディスクを追加し、Windows Serverの記憶域スペース(Storage Spaces)を使用して複数のディスクでシンプル(Simple)またはパリティ(Parity)記憶域にします。だたし、最大のデータディスク数もVMのサイズで決まっています。
VMのサイズの概要|Azure(MicrosoftLearn)
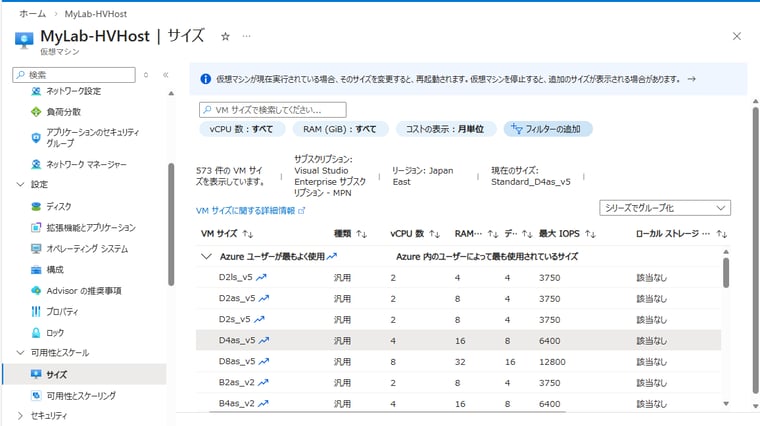
画面6 VMのサイズによって利用可能なIOPSとスループットに上限が決まっている
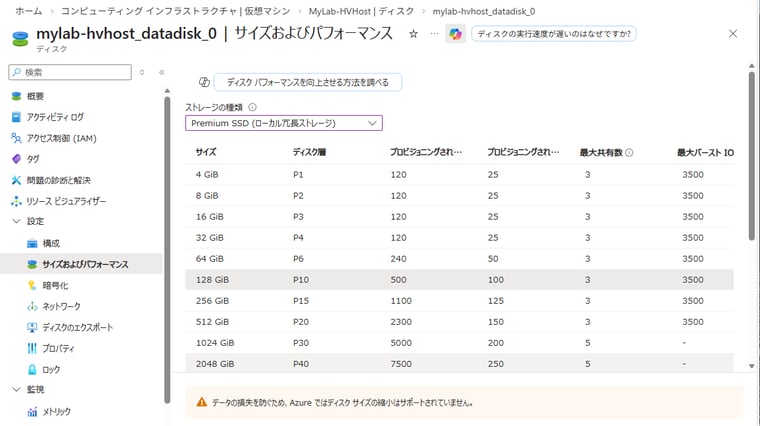
画面7 マネージドディスクの種類やサイズでもIOPSとスループットの上限がある
Azureのプラットフォーム側が提供するIOPSやスループットの上限は、VMのゲストからは監視できません。Azure Monitorを使用すると、Azure VMをホストするサーバーのメトリック(ホストメトリック)を監視することができます。ホストメトリックには、以下に示すような、VMのゲストからは参照できないパフォーマンスデータを取得できます(画面8)。
-
CPU Credits Consumed
-
CPU Credits Remaining
-
Data OS/Disk Bandwidth Consumed Percentage
-
Data OS/Disk IOPS Consumed Percentage
-
Data OS/Disk Max Burst Bandwidth
-
Data OS/Disk Max Burst IOPS
-
Data OS/Disk Target Bandwidth
-
Data OS/Disk Target IOPS
-
Data OS/Disk Used Burst BPS Credits Percentage
-
Data OS/Disk Used Burst BPS Credits Percentage
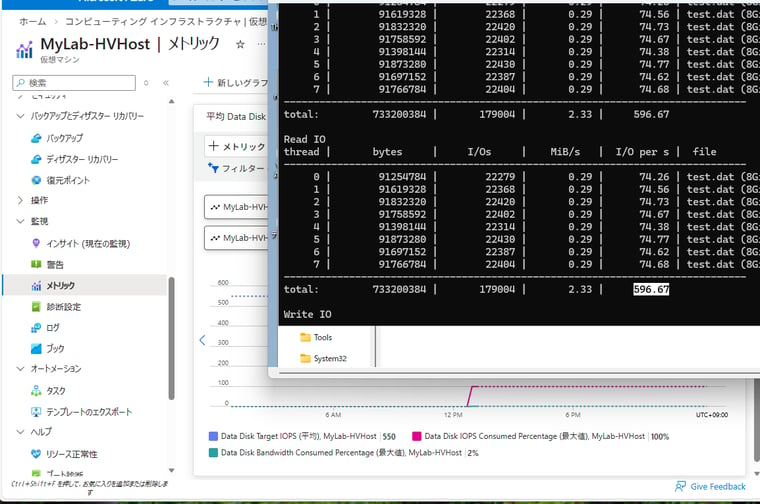
画面8 ディスクのIOPSやスループットは、VMのサイズやディスクの種類とサイズで上限がある。この例では1台のディスクあたりのブースとなしで利用できるIOPSの上限は550(VMの仕様上は500を保証)であり、現在、100%消費しているのがわかる
参考:
Azure Virtual Machines の監視データのリファレンス|Azure(Microsoft Learn)
Azure VMのホストメトリックをゲスト側から監視したい-BOM for Windows活用例|製品コラム
セイテク・シス管道場(Web) (1) |(2)|(3)|(4) |(5)|(6) |(7)|(8)|(9)|(10)|(11)|(12)|(13)|(14)|(15)




