
「セイテク・シス管道場(Web)」では、Windows Serverの要素技術やシステム管理の基本的な部分に焦点を当ててきました。間もなくシリーズ最終回、最後のテーマはWindowsにおける文字コード(エンコード)の話です。
ANSIなら安心という思い込み
“ANSIで保存しておけば安心」――そう思っていませんか?
バッチファイル(拡張子.bat、.cmd)を作成するときは、メモ帳でコードを記述して、エンコード「ANSI」で保存する、当たり前のようにそうしている人は多いと思います。Windowsのメモ帳の既定がUTF-8(BOMなし)に変更されてから(Windows 10バージョン1903~)、特に気を付けている人は多いと思います。
さて、このANSIですが、「American National Standards Institute」の略として知られています。文字コード(エンコード)に関する統一規格のように見えるかもしれませんが、Windowsの世界におけるANSIの正体は、統一規格ではなく、その環境で使用されているアクティブなコードページのことを指す、実質的にWindowsの文脈での用語です。そして、日本語版Windowsのアクティブのコードページは「CP932」です。
CP932はShift_JIS(JIS規格)をベースにMicrosoftが拡張したもので、「Windows-31J」とも呼ばれています。これは、Windows 3.1時代に定義された古い文字コード(エンコード)です。そのため、Shift_JISと厳密に同一ではありません。ただし、ANSI=CP932は、日本語版Windowsの話です。古くから多言語対応していたWindowsは、言語ごとにコードページを持っています。つまり、共通のエンコードとしてのANSIが通用するのは、同じコードページで動作しているWindows環境の間だけです。日本語版Windows同士、あるいは日本語を追加して表示言語を切り替えた環境などに限られます。このことを意識している人は、意外と少ないかもしれません。
そもそもコンピューターの初期は、英数字と記号だけを扱うASCIIコードがあれば十分でした。しかし、多言語対応が求められるようになると、DOS/Windowsでは各言語圏ごとに独自の拡張が行われ、コードページという形で文字コードが分断されていきます。一方、UNIXなどの他のプラットフォームでも、EUC-JPやShift_JIS、ISO-2022-JPといった複数の文字コードが併存し 、統一されているとは言えない状況でした。その結果、異なるプラットフォーム間はもちろんのこと、同じWindows間であっても環境が異なれば文字が正しく扱えない問題が生まれました。こうした状況を解消するために登場したのが、すべての文字を統一的に扱うUnicodeです。
話をANSIに戻しましょう。例えば、日本語版Windowsで日本語を含む「demo_jp.txt」をエンコード「ANSI」を指定して保存します。また、英語版Windowsで西欧文字で書いた「demo_en.txt」を同じようにエンコード「ANSI」を指定して保存します。作成したテキストをそれぞれ交換して、メモ帳で開いてみます。英語版Windowsでは日本語部分は文字化けするでしょう(画面1)。この文字化けの原因はフォントの有無とは関係ありません。英語版および他の数種の西ヨーロッパ言語版Windowsの既定のコードページはラテン文字のエンコード「CP1252」だからです。同じANSIでもコードページが違えば正しく読むことはできません。同じ理由で、日本語版Windowsで「demo_en.txt」の一部の文字は文字化けします(画面2)。
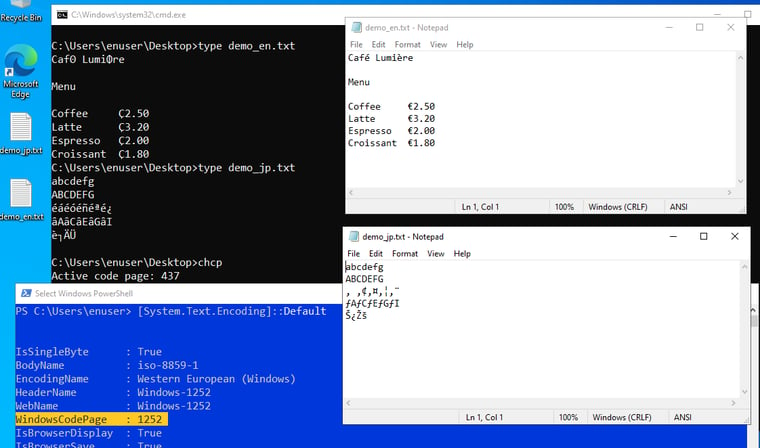
画面1 日本語が文字化けしているのは、フォントの問題ではなく、書かれた環境と表示している環境でアクティブなコードページが違うため
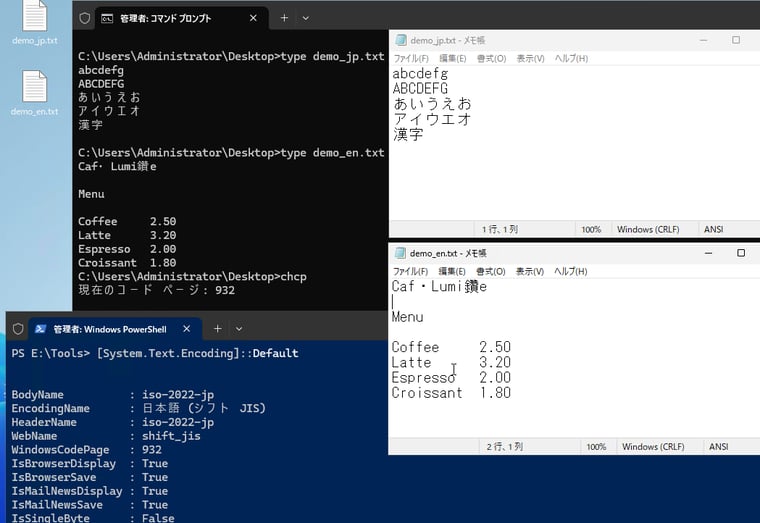
画面2 「demo_en.txt」のéやèや€が文字化け、1行目は隣の文字にも影響
英語版Windowsでは、メモ帳とコマンドプロンプト(cmd.exe)で「demo_en.txt」の表示が異なることにも注目してください。日本語版Windowsでは、システムとcmd.exeのコードページはどちらもCP932ですが、英語版Windowsでは、システムはCP1252、cmd.exeはCP437で異なります。CP437は初代IBM PCの標準文字コードとして知られています。その結果、英語版Windowsのcmd.exeではéやèや€を正しく表示できていません。その理由もまたコードページの違いです。
互換性にこだわった結果、Windowsに生まれたカオスな世界
CP932が生まれた当時、Windowsだけでもコードページの違いに加え、UNIX、Mac(Classic)といった各プラットフォームでも、それぞれ異なる文字コード、異なる改行文字(WindowsはCRLF、Unix/Linux/macOSはLF、古いMacOSはCR)が使われており、データのやり取りをするだけでも一苦労で、まさにカオスな世界でした。現在では、UNIX、Linux、macOSの多くでは文字コードUTF-8(BOMなし)、改行文字LFでほぼ統一されています。Windowsは文字コードも改行文字も、正しく扱うにはアプリケーション側の対応に依存している状況です。例えば、新しいメモ帳は改行文字を「Windows(CRLF)」「Unix(LF)」「Macintosh(CR)」と正しく認識して表示できますが、昔のメモ帳(ANSIが既定だったWindows 10バージョン1809、Windows Server 2019以前のメモ帳)はどちらも改行が失われて表示していました。
一方でWindowsはというと、現在のWindowsの基盤となるWindows NT 3.1(1993年)からUnicode対応が導入され、内部文字コードとしてUnicode(UTF-16LE)が採用されました。このとき、WindowsのAPIには、従来のANSIに対応したANSI(A)バージョンとUnicodeに対応したUnicode(W)バージョンの2つのエントリポイントを用意されるようになりました。CreateFileを例に見ると、実際にはCreateFileA関数とCreateFileW関数の2つが存在します。ANSI版の関数は、入力時にANSIからUnicodeへ、出力時にUnicodeからANSIへ変換を行い、実際の処理はUnicode版が担当します。つまり、ANSI版の関数が残されているのは完全に互換性のためであり、それがWindowsの下位互換性の強みでもあります。
しかし、この構造は現在も変わっていません。Windowsの内部はUnicode(UTF-16LE)で統一されている一方で、外部とのやり取りにはいまだにコードページが各所で使われ続けています。
例えば、日本語のフォルダー名やファイル名は“Shift_JISで扱われている”と思っていないでしょうか。実際には、Windows内部ではこれらもすべてUnicodeで管理されています。NTFSボリュームでは、ファイル名はMFT内にUnicodeで格納されています。 cmd.exeではCP932(コードページ)を使って表示・入出力が行われ、PowerShellではUTF-16 LEやUTF-8が使われます。さらに、Windows Subsystem for Linux(WSL)からはWindowsのファイルシステムをUTF-8として扱うことができます。 このように、実体は同じでも、アプリケーションごとに見え方が変わっているにすぎません。そしてデータ(ファイル)の中身については、アプリケーションがエンコードを判別できない限り、正しく表示することはできません(画面3)。
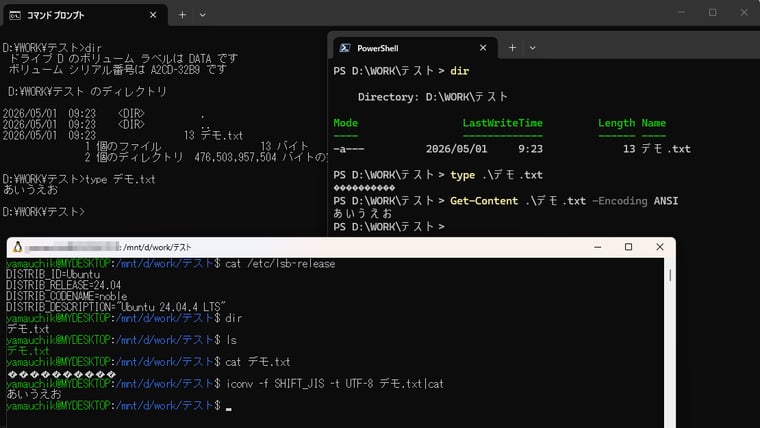
画面3 ディレクトリ名やファイル名、cmd.exeはANSI(CP932)、PowerShell(pwsh.exe)やWSLではUTF-8で見えている
つまり、Windowsは完全にUnicodeへ移行したわけではなく、両者が共存する状態がずっと続いているのです。そしてそれは、今後も続くであろう、どこか歪でカオスな世界なのです。
では実際に、バッチやPowerShellではどう使い分ければいいのか? 次回(最終回)で解説します。
セイテク・シス管道場(Web) (1) |・・・|(10)|(11)|(12)|(13)|(14)|(15)|(16)|(17)|(18)|(19)|(20)|(21)|(22)|(23)




